Bare Minimum Crates.io Mirror Plus One
I’ve been interested for a long time in making it easier to set up a mirror of crates.io. Making our vibrant ecosystem of libraries highly available around the world, on the public internet and within corporate firewalls, will help drive adoption and increase trust in our new community.
I enjoyed and learned a lot from Gary Josack’s Dissecting Crates.io: Bare Minimum Mirror post and I’ve gotten to the point where I’ve built one more step on top of that post! His mirror is all local on his computer; mine runs in the cloud.
TL;DR
I now have:
- A download-API mirror of crates.io running at cratesio-mirror.herokuapp.com
- A registry index mirror at gitlab.com/integer32llc/crates.io-index that is scheduled to pull from crates.io’s index every 10 min
And, because of some changes that were just added to Cargo that went out with the Rust 1.12.0 release, I’m able to easily tell Cargo to use these instead of crates.io to be able to download crates.
Note that the crates’ files themselves are still coming from crates.io’s S3 bucket, and both my app and crates.io are hosted on Heroku, so this would only gain the community resiliency if:
(
GitHub was inaccessible, since my registry index is on GitLab
OR (
crates.io's app was inaccessible for some reason
AND
Heroku in general stayed accessible
)
)
AND
crates.io's S3 bucket stayed accessible
So this isn’t total, separate redundancy, but it’s a little bit more than we have now.
There are some other disadvantages/annoyances to using my mirror:
- There’s no crate information available in the web UI, so you couldn’t search for crates if crates.io was inaccessible.
- You can’t publish to my mirror, so you couldn’t share new crates if crates.io was inaccessible.
I’d like to share what I learned through this process by talking about how Cargo works with the registry index and crates.io to download crates for you, then talk about how to set up your own API server and registry index, and finally how you tell Cargo that you want to use a mirror instead of crates.io. I’ll wrap up with what I see as logical next steps for continuing this work that I plan to do and would love to collaborate with people on!
How Cargo downloads crates
My first step in making a working mirror was understanding what happens when
you have dependencies specified in your Cargo.toml, you don’t have those
crate files on your computer yet, and you run cargo build. Where do those
files come from, and how does Cargo know that?
Based on a comment Alex Crichton made on my issue about running a
mirror , I knew that the pieces were cargo running on my
computer, the registry index on GitHub, and
crates.io, but I wasn’t sure how these interacted.
By doing git grep crates.io in Cargo’s codebase, I found the
constant CRATES_IO that’s hardcoded to
https://github.com/rust-lang/crates.io-index for Cargo’s default
registry source, so that’s how Cargo knows where to find the index. I did not
find anywhere the code knew about https://crates.io, but I followed what
Cargo does with the index: it does a git fetch, then in addition to all the
files containing metadata on crates, in the index repo is a config.json
file that contains crates.io URLs:
{
"dl": "https://crates.io/api/v1/crates",
"api": "https://crates.io/"
}
When Cargo goes to download a crate, it takes the value for dl in
the config.json and concatenates the crate name, the version, and the string
“download” separated by slashes and then requests that URL. For example, if we
wanted the crate zopfli version 0.3.3, Cargo would create the url
https://crates.io/api/v1/crates/zopfli/0.3.3/download.
If we then switch to crates.io’s codebase and look at what the download route does, we can see that it redirects to a different URL created in this manner:
let redirect_url = format!("https://{}/crates/{}/{}-{}.crate",
req.app().bucket.host(),
crate_name, crate_name, version);
crate_name and version came from the download URL, and in our example are
“zopfli” and “0.3.3”, respectively. But what is req.app().bucket.host() set
to for the production crates.io instance? The value ultimately comes from an
environment variable, and we don’t have access to crates.io’s
environment variables directly. But we do have access to the redirect URL; if
we didn’t, we wouldn’t be able to download any crates! It was easiest for me to
see by requesting a download URL using curl:
$ curl -v https://crates.io/api/v1/crates/zopfli/0.3.3/download
...
< HTTP/1.1 302 Found
...
< Location: https://crates-io.s3-us-west-1.amazonaws.com/crates/zopfli/zopfli-0.3.3.crate
...
A-HA! So the crate files are actually coming from an S3 bucket at
crates-io.s3-us-west-1.amazonaws.com.
Now we now how all these parts fit together:

What Gary’s post did was make all of these different parts come
from your computer by getting a local checkout of the registry index, pointing
the config.json at a Python SimpleHTTPServer running locally with
already-downloaded crate files in a file structure that matched the API paths,
and configuring Cargo to use the local registry instead (differences shown in
orange):
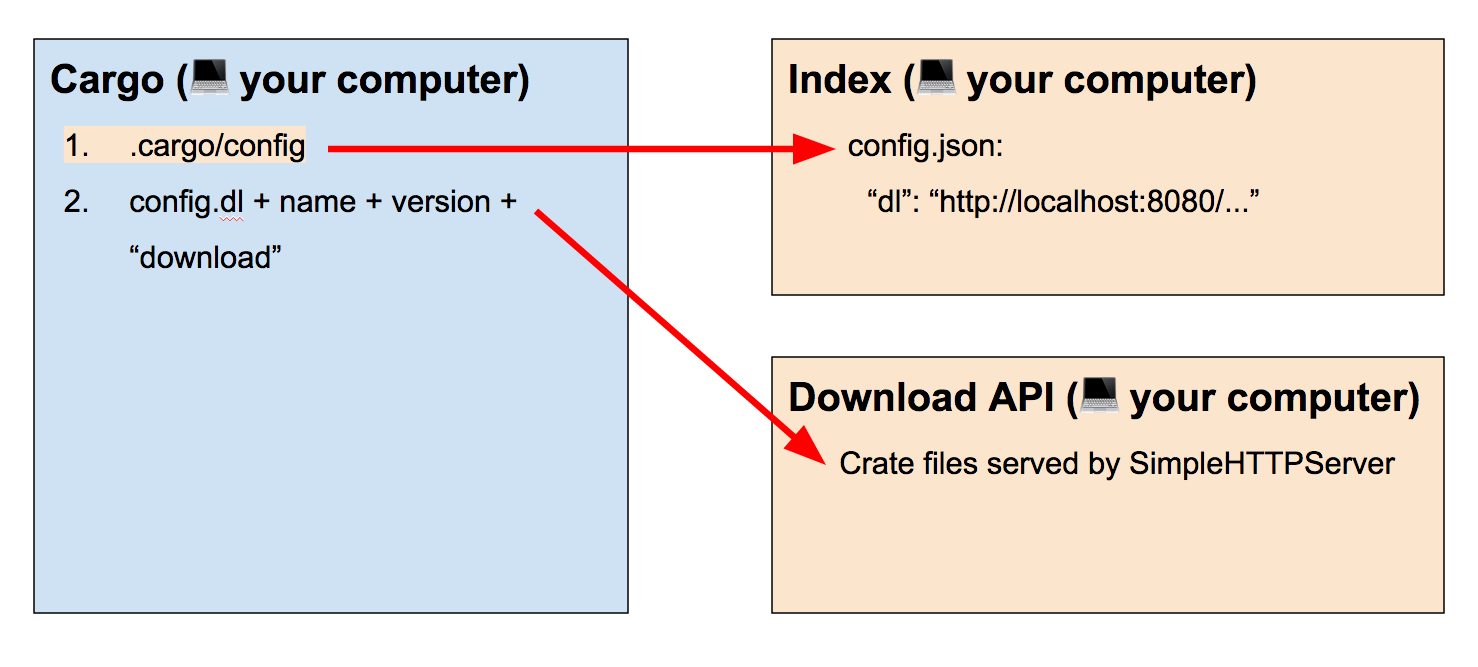
There’s no need for a redirect with this setup since the files are already exactly where Cargo is looking for them!
What I set out to do was to have the registry index be on GitLab, the download API be a different Heroku app, but for now still get the crate files from crates.io’s S3 bucket:
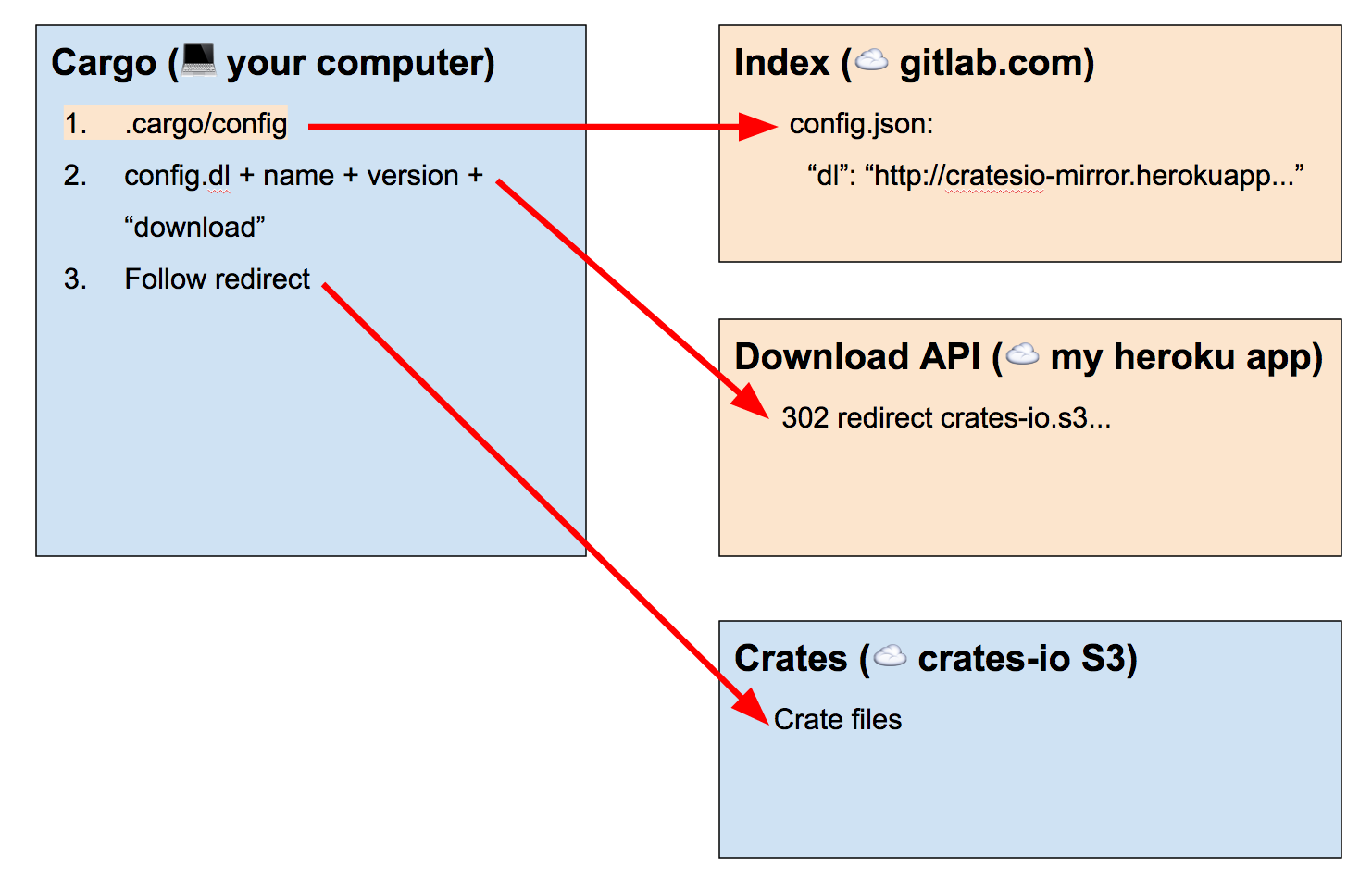
This is fine since we’re just reading the crate files, not writing to the S3 bucket, which we couldn’t anyway since we don’t have crates.io’s keys :)
So that’s what I did, now let’s talk about how!
How to set up an API server
Alex recently merged a pull request of mine to add a “Deploy to Heroku” button to crates.io’s README! So getting your own Heroku instance of crates.io’s API is just a few clicks away. Also note that this app will happily run on Heroku’s hobby tier if you have free dyno hours available.
The only Heroku configuration variable that you should change is the
GIT_REPO_URL pointing to your registry index. And your registry index will
need to point to your API server. Yes, you are now in a deadlock. Don’t worry,
we’ll fix it. Clone the index repo, push it up where you want
it to be, specify that URL in the GIT_REPO_URL var, deploy your Heroku
instance, and keep reading for how to finish setting up your index!
How to set up a registry index on GitLab
I chose to put my mirror index on GitLab to get some different infrastructure mixed in. Doing similar steps on GitHub is left as an exercise for the reader; the concepts are the same :)
Once you’ve got a clone of the official index, edit the config.json file in
it to point the URL values at your Heroku app. Mine is
https://cratesio-mirror.herokuapp.com/, so my config.json
looks like:
{
"dl": "https://cratesio-mirror.herokuapp.com/api/v1/crates",
"api": "https://cratesio-mirror.herokuapp.com/"
}
Commit this and push it to your index’s repo. At this point, we can make sure everything’s hooked up correctly by trying it out with Cargo!
How to tell Cargo to use a mirror
You’ll need the version of Cargo that was released with Rust version 1.12.0 recently.
In a Cargo project, create a .cargo/config file if you don’t already have
one, and specify that you want to replace the crates.io source with your
mirror like this:
[source]
[source.mirror]
registry = "https://gitlab.com/integer32llc/crates.io-index"
[source.crates-io]
replace-with = "mirror"
registry = "https://doesnt-matter-but-must-be-present"
I had another PR just get merged so that it won’t be necessary to specify a registry URL for a source being replaced, but that just got into Cargo beta. So for now, the value put in there will be ignored since you’re replacing that source anyway, but it does need to be present.
Now you should be able to cargo build and see the mirror registry in the
output!
Updating registry `https://gitlab.com/integer32llc/crates.io-index`
Downloading regex v0.1.77 (registry https://gitlab.com/integer32llc/crates.io-index)
How to keep the registry index updated
You’ve got crates coming through your mirrored registry and API server, but
new crates get added to the registry all the time, and your registry won’t know
about them. So your registry needs to fetch from the official registry and
merge that in– that is, a scheduled task that does git fetch upstream, git
merge upstream/master, and git push origin. The merge does have the
possibility of failing if the official crates registry changes config.json
since we’ve modified that file. I don’t know of any plans to change that file
at this time, so I think that risk is acceptable to trade off in order to get
simplicity in this command. An exercise for the reader would be to set this up
to send an email to you if any part fails.
There are a number of ways you could go about doing this; it could be as simple
as cron running a shell script. I decided to go with a Heroku scheduled job
that triggers a GitLab runner.
GitLab includes a CI service similar to Travis CI. I decided to give GitLab’s a try since my registry repo is already on GitLab. A wrinkle is that by default, the CI service only has read access to your repository, while we need write access. The solution to this is to use the Variables feature of the CI service to give the script an SSH key it can use to get write access to your repository.
Follow these instructions to generate a new SSH key and add the public key to your user profile. I recommend creating a new one instead of reusing an existing one so that you can remove just this one in case you need to revoke access of just the CI service but not you.
Go to your registry repo and in the gear menu, choose “Variables”. Create a
variable with the key SSH_PRIVATE_KEY and paste your private key as the
value.
Create a .gitlab-ci.yml file in the root of your registry repo that looks
like this, filling in any parts in brackets with the appropriate information.
This example from GitLab helped me figure out what needed to go
here:
before_script:
# install ssh-agent
- 'which ssh-agent || ( apt-get update -y && apt-get install openssh-client -y )'
# run ssh-agent
- eval $(ssh-agent -s)
# add ssh key stored in SSH_PRIVATE_KEY variable to the agent store
- ssh-add <(echo "$SSH_PRIVATE_KEY")
# disable host key checking (NOTE: makes you susceptible to man-in-the-middle attacks)
# WARNING: use only in docker container, if you use it with shell you will overwrite your user's ssh config
- mkdir -p ~/.ssh
- echo -e "Host *\n\tStrictHostKeyChecking no\n\n" > ~/.ssh/config
update:
only:
- triggers
script:
- git config user.name "[Your name]"
- git config user.email "[Your email]"
- git remote set-url origin git@gitlab.com:[Your gitlab username]/crates.io-index.git
- git checkout master
- git reset --hard origin/master
- git remote add upstream https://github.com/rust-lang/crates.io-index.git
- git fetch upstream
- git merge upstream/master
- git push origin master
The only: triggers setting means this job will only run if triggered. The
default is to run every time the repository gets updated, but if it did that,
the CI jobs would get in an infinite loop since the job updates the repository!
Go to your registry repo’s Pipelines tab and use the “Run pipeline” button to test out the job. If it works correctly, the repo should have additional commits from upstream for all the crates that were uploaded to crates.io between when you first created your repository and now.
It’d be nice if GitLab allowed scheduling of pipeline jobs, but it doesn’t yet (although GitLab is open source so you could add it!) Instead, set up a Heroku Scheduler to trigger the job. In GitLab, go to the gear menu on your registry repo, go to “Triggers”, and click the “Add trigger” button to create a new token. Also note the command under the “Use cURL” section further down that page: it contains your project’s ID that you’ll need in the next step.
Create a new Heroku app that just has the Heroku Scheduler add-on. Add a job and choose how often you want it to run (I chose 10 min). For the command to run, enter this (again replacing anything in brackets with your information):
curl -X POST -F token=[Your trigger token] -F ref=master https://gitlab.com/api/v3/projects/[Your project id]/trigger/builds
Wait for that to run and go check your GitLab repository; if there were crates published in the time since you last ran the CI job, you should see another merge commit in your repo! If you don’t, check your Heroku logs to diagnose what went wrong.
The last step to check all this is to go back to your project that has Cargo
configured to use your mirror and try to add a recently-published version to
that project and cargo build. If all went well, you should have that new
crate downloaded through your mirror! Congrats!
Next steps
Here are the most immediately possible of my many ideas about where this work could go next:
- Provide redundancy with the crates’ files too, by caching the files from S3
when they’re requested. Alex’s work on
cargo vendoris probably relevant here. Not sure of the actual implementation I want to try yet– not disturbing or complicating the code that runs on the main crates.io instance (which wouldn’t need to cache files) is important! - Perhaps when we cache a crate’s files, also add the crate info to the mirror’s database, so that we could search in the frontend for at least the crates that we’ve cached.
- Once you have a cache of the files, you might want to invalidate that cache to save space and not keep around old files you’re not even using anymore. But that’s hard.
- Package up the API server and the registry index and the registry index updating into one easy-to-deploy app. Somehow.
So there’s lots to do! Baby steps :)
Are these instructions not working? Open an issue for me on this blog’s repo or contact me.